Understanding V8’s Compiler Pipeline
Introduction
V8 is the JavaScript engine powering browsers like Google Chrome, Brave, and Microsoft Edge. This series of blog posts will go into the internals of V8. This first part will be giving an overview of the V8 Compiler Pipeline.
Compiler Pipeline
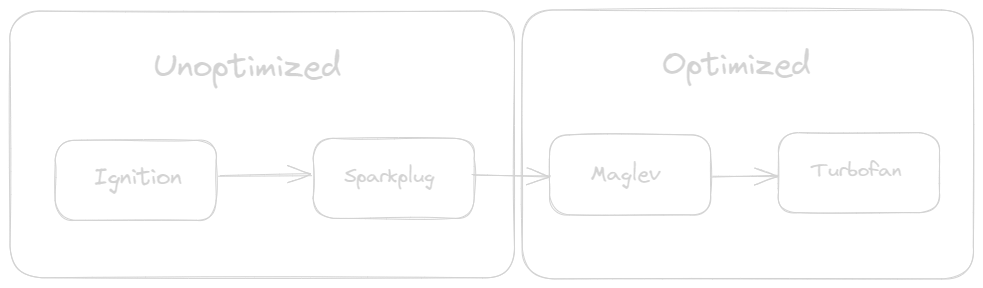
High-Level Overview: The Life Cycle of a JavaScript Source in the V8 Engine
Just-In-Time (JIT) Compilation involves executing bytecode through an interpreter VM, which is slower than running machine code directly. Most compilers, including V8, follow a similar initial compilation pipeline:
- Source Code to Abstract Syntax Tree (AST)
- AST to Bytecode
V8 begins by converting source code into tokens, which are then transformed into an AST. This AST is subsequently converted into V8 bytecode. The AST serves as an Intermediate Representation (IR), providing a layer of abstraction used for translation and optimization.
Parser
JavaScript code first passes through a parser, which breaks down the code into tokens (a process called tokenization). These tokens are then converted into an Abstract Syntax Tree (AST).
Ignition
Ignition, the interpreter stage, walks through the AST, converting it into V8 bytecode and executing it.
Sparkplug
Sparkplug is a non-optimizing compiler stage that iterates over the bytecode generated by Ignition, converting it into machine code for each bytecode as it loops.
Maglev
Maglev marks the start of optimizations in machine code. It’s a mid-tier optimizing compiler that gets type feedback from the interpreter after static analysis. This feedback is used make some quick optimizations on a graph it creates called “Maglev IR”.
Turbofan
In the Turbofan phase, JIT compilation occurs, translating bytecode into highly optimized machine code.
Hot Functions and Tiered Compilation
When a JavaScript function is executed repeatedly, it becomes ‘hot’ and is sent to the next tier in the pipeline. Each tier gathers profiling information during multiple executions, aiding speculative optimization. To validate the optimized code, checks are placed in the optimized code. If the function behaves unexpectedly, i.e the checks fail, it deoptimizes
Why Is Optimization Necessary?
Consider a simple operation like a + b. In JavaScript, unlike ahead-of-time compiled languages like C/C++, the engine doesn’t initially know the types of the variables involved. The operation could be an integer addition or a string concatenation. Based on the ECMAScript Specification, V8 performs various checks whenever it encounters a “+” to determine the correct operation.
Here’s the ECMAScript Specification for the “+” Operator:
13.8.1 The Addition Operator ( + )
NOTE
The addition operator either performs string concatenation or numeric addition.
13.8.1.1 Runtime Semantics: Evaluation
AdditiveExpression : AdditiveExpression + MultiplicativeExpression
1. Return ? EvaluateStringOrNumericBinaryExpression(AdditiveExpression, +, MultiplicativeExpression).
13.15.4 EvaluateStringOrNumericBinaryExpression ( leftOperand, opText, rightOperand )
The abstract operation EvaluateStringOrNumericBinaryExpression takes arguments leftOperand (a Parse Node), opText (a sequence of Unicode code points), and rightOperand (a Parse Node) and returns either a normal completion containing either a String, a BigInt, or a Number, or an abrupt completion. It performs the following steps when called:
1. Let lref be ? Evaluation of leftOperand.
2. Let lval be ? GetValue(lref).
3. Let rref be ? Evaluation of rightOperand.
4. Let rval be ? GetValue(rref).
5. Return ? ApplyStringOrNumericBinaryOperator(lval, opText, rval).
13.15.3 ApplyStringOrNumericBinaryOperator ( lval, opText, rval )
The abstract operation ApplyStringOrNumericBinaryOperator takes arguments lval (an ECMAScript language value), opText (**, *, /, %, +, -, <<, >>, >>>, &, ^, or |), and rval (an ECMAScript language value) and returns either a normal completion containing either a String, a BigInt, or a Number, or a throw completion. It performs the following steps when called:
1. If opText is +, then
a. Let lprim be ? ToPrimitive(lval).
b. Let rprim be ? ToPrimitive(rval).
c. If lprim is a String or rprim is a String, then
i. Let lstr be ? ToString(lprim).
ii. Let rstr be ? ToString(rprim).
iii. Return the string-concatenation of lstr and rstr.
d. Set lval to lprim.
e. Set rval to rprim.
2. NOTE: At this point, it must be a numeric operation.
3. Let lnum be ? ToNumeric(lval).
4. Let rnum be ? ToNumeric(rval).
5. If Type(lnum) is not Type(rnum), throw a TypeError exception.
6. If lnum is a BigInt, then
a. If opText is **, return ? BigInt::exponentiate(lnum, rnum).
b. If opText is /, return ? BigInt::divide(lnum, rnum).
c. If opText is %, return ? BigInt::remainder(lnum, rnum).
d. If opText is >>>, return ? BigInt::unsignedRightShift(lnum, rnum).
7. Let operation be the abstract operation associated with opText and Type(lnum) in the following table:
opText Type(lnum) operation
** Number Number::exponentiate
* Number Number::multiply
* BigInt BigInt::multiply
/ Number Number::divide
% Number Number::remainder
+ Number Number::add
+ BigInt BigInt::add
- Number Number::subtract
- BigInt BigInt::subtract
<< Number Number::leftShift
<< BigInt BigInt::leftShift
>> Number Number::signedRightShift
>> BigInt BigInt::signedRightShift
>>> Number Number::unsignedRightShift
& Number Number::bitwiseAND
& BigInt BigInt::bitwiseAND
^ Number Number::bitwiseXOR
^ BigInt BigInt::bitwiseXOR
| Number Number::bitwiseOR
| BigInt BigInt::bitwiseOR
8. Return operation(lnum, rnum).
All these steps for a seemingly simple addition highlight why optimization is crucial. V8 engages in “speculation” during the execution of JavaScript code, collecting information to use when the engine decides to tier up, thus producing optimized code.
Speculative Optimization
Due to the dynamic nature of JavaScript, there’s little initial information about the code to be executed. Consider a function func adding two variables x and y, which are expected to be numbers. V8 can optimize by skipping checks if it knows x and y are numbers through repeated execution and profiling.
After Ignition generates the bytecode, the bytecode runs for a while. This is when the code gets ‘hot’. Meanwhile, it gathers feedback and stores it in the Feedback Vector(which is the structure containing the profiling data)``
The Feedback Vector stores all the information about the loads, stores, etc. This bytecode, along with the feedback vector, is fed into the next tier of the compilation pipeline.
The purpose of this process is to speculate about the code and produce optimized code.
Sea Of Nodes
The Turbofan first converts each bytecode instruction into a collection of nodes which results in a representation called Sea of Nodes. It combines aspects of both Data Flow Graphs (DFG) and Control Flow Graphs (CFG).
Sea of Nodes graphs have three types of edges:
-
Value Edges: Represent the flow of data between operations.
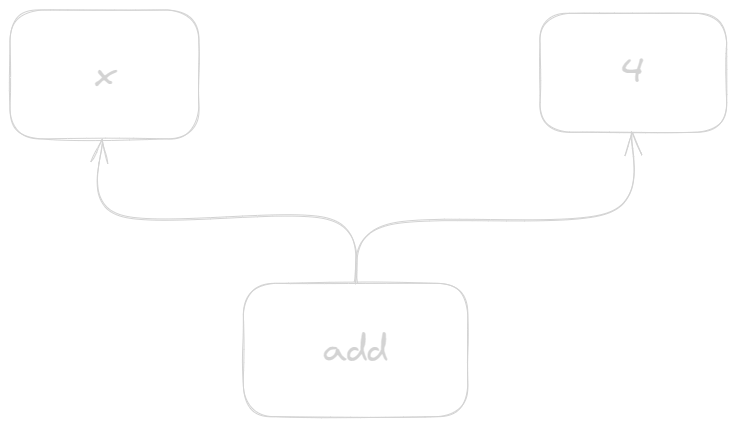
-
Control Edges: Dictate the program’s control flow.
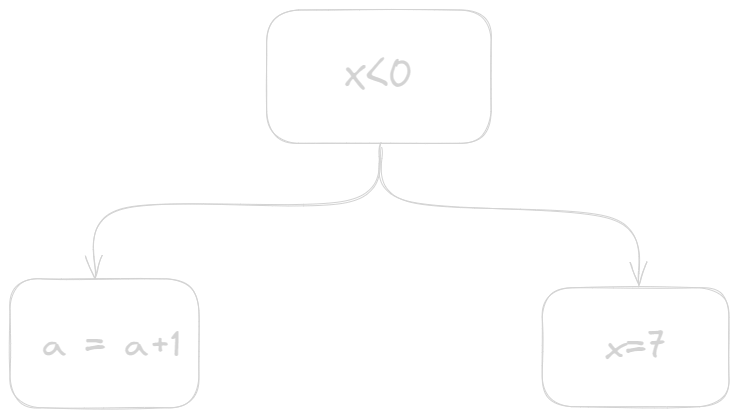
-
Effect Edges: Ensure operations are executed in the correct order.
So, all the optimizations happen in the sea of node graph.
Next part of this series will be focusing on Turbofan and how it uses Sea of Nodes during various optimizations phases.